






Descubra o que é o Ollama e como ele permite rodar LLMs como o Llama 3 localmente, garantindo privacidade, agilidade e controle.
No cenário tecnológico atual, a inteligência artificial (IA) e, em particular, os Modelos de Linguagem Grandes (LLMs), como o ChatGPT, têm revolucionado a forma como interagimos com a informação. Porém, muitas delas dependem de nuvem, e é nesse cenário que o Ollama surge como uma solução poderosa.
Para um gerente de TI, por exemplo, a complexidade na migração para a nuvem, os custos imprevisíveis e as preocupações com a segurança de dados são desafios diários. O Ollama atende a essas dores, oferecendo uma alternativa que valoriza o custo-benefício, a facilidade de integração e, acima de tudo, a segurança de dados.
Prepare-se para saber um pouco mais sobre o Ollama e descobrir como ele pode transformar sua experiência com IA, oferecendo um novo nível de autonomia e eficiência. Confira!

O que é o Ollama e por que pode ser útil para você
O Ollama é uma plataforma inovadora que simplifica drasticamente a execução de Modelos de Linguagem Grandes (LLMs) em sua máquina local.
Imagine ter a capacidade de interagir com modelos avançados como o Llama 3, Mistral ou Gemma, sem a necessidade de uma conexão constante com a internet. Essa é a promessa do Ollama: empacotar modelos de linguagem, suas dependências e configurações necessárias em um formato fácil de usar.
Em sua essência, o Ollama funciona como um runtime para LLMs. Isso significa que ele fornece o ambiente e as ferramentas necessárias para que esses modelos complexos sejam executados de forma eficiente em sistemas operacionais como Linux, macOS e Windows.
Porém, a grande sacada do Ollama é abstrair a complexidade de configurar ambientes de desenvolvimento, gerenciar dependências e otimizar o hardware para cada modelo específico. Ele oferece um sistema de “pacotes” onde cada modelo vem pré-configurado e pronto para uso, bastando um comando para baixá-lo e outro para começar a interagir.
Este design focado na simplicidade torna o Ollama uma ponte acessível entre os usuários e o poder dos LLMs de código aberto, incentivando a inovação e a experimentação sem as barreiras técnicas que antes existiam.
Vantagens de executar modelos em sua máquina
Executar LLMs localmente com o Ollama traz uma série de benefícios que impactam diretamente na experiência do usuário.
Privacidade aprimorada
Esta é, talvez, a maior vantagem. Ao processar dados em sua própria máquina, você garante que informações sensíveis não saiam do seu ambiente. Isso é crucial para empresas que lidam com dados confidenciais ou para usuários que prezam pela discrição em suas interações com a IA.
Para um gerente de TI, a segurança de dados é uma prioridade, e o Ollama oferece uma solução direta para mitigar riscos de vazamento.
Velocidade e baixa latência
A comunicação com servidores remotos sempre introduz um atraso. Com o Ollama, as interações com o modelo são quase instantâneas, já que o processamento ocorre diretamente em seu hardware.
De maneira geral, isso é especialmente perceptível em tarefas que exigem respostas rápidas, como chatbots ou assistentes de código. Afinal, a agilidade é um fator-chave para otimizar o fluxo de trabalho e aumentar a produtividade.
Controle total
Aqui, você está no comando e pode escolher exatamente quais modelos deseja usar, como configurá-los e quando atualizá-los. Não há preocupações com interrupções de serviço de terceiros ou mudanças inesperadas nas políticas de uso.
Custo-benefício
A dependência de APIs de nuvem pode levar a custos imprevisíveis, com base no volume de uso. Com o Ollama, o custo é fixo e associado ao hardware que você já possui.
Após o investimento inicial, você pode usar os modelos de forma intensiva sem se preocupar com a fatura mensal. Isso oferece um custo-benefício superior, especialmente para projetos com uso de IA em grande escala.
Personalização e experimentação
Desenvolvedores podem ajustar e experimentar com os modelos de forma mais livre, testando diferentes parâmetros e integrando-os em suas próprias aplicações sem restrições externas. Isso, por sua vez, acelera o ciclo de inovação.
Acessibilidade offline
Uma vez que o modelo é baixado, você pode usá-lo mesmo sem conexão com a internet, o que é ideal para trabalho em campo ou em locais com conectividade limitada.
A capacidade de manter a IA local transforma a forma como pensamos sobre segurança e autonomia digital, tornando o Ollama uma ferramenta essencial para o futuro da computação pessoal e corporativa.
Como o Ollama funciona
O Ollama foi projetado para ser intuitivo e eficiente, abstraindo grande parte da complexidade técnica de rodar LLMs.
Em sua essência, ele atua como um servidor local que hospeda e gerencia os modelos, permitindo a interação através de diferentes interfaces. Essa abordagem simplifica o processo de uso de LLMs para desenvolvedores e entusiastas.
Ambiente isolado com modelos, pesos e dependências pré-configuradas
A mágica do Ollama reside em seu sistema de “modelos” empacotados. Cada modelo que você baixa (como llama3, mistral, etc.) vem como um pacote autocontido, que inclui não apenas os “pesos” do modelo (os dados que o modelo usa para gerar respostas), mas também todas as dependências de software necessárias para seu funcionamento.
Com essa mecânica, ele cria um ambiente isolado para cada modelo, evitando conflitos de versão e simplificando a instalação. Quando você executa um comando para rodar um modelo, o Ollama:
- Verifica se o modelo já está em seu sistema;
- Se não estiver, ele o baixa de seu repositório central;
- Carrega o modelo na memória, otimizando-o para o seu hardware (CPU e/ou GPU);
- Expõe uma interface para que você possa enviar prompts e receber respostas.
Esse sistema de empacotamento garante que a experiência seja consistente, independentemente do modelo ou do sistema operacional que você esteja usando. Além disso, torna a instalação de novos modelos tão simples quanto digitar um comando.
Interface de linha de comando (CLI): comandos essenciais
A principal forma de interação com o Ollama é através da sua poderosa Interface de Linha de Comando (CLI). Com alguns comandos simples, você pode baixar modelos, iniciar sessões de chat e gerenciar seus LLMs.
Aqui estão alguns comandos essenciais:
- ollama pull <nome_do_modelo>: baixa um modelo específico para o seu sistema. Por exemplo, ollama pull llama3;
- ollama run <nome_do_modelo>: inicia uma sessão interativa com o modelo. Você pode começar a digitar suas perguntas e o modelo responderá. Exemplo: ollama run mistral. Para sair, digite /bye;
- ollama list: exibe todos os modelos que você baixou e instalou em sua máquina;
- ollama rm <nome_do_modelo>: remove um modelo do seu sistema, liberando espaço em disco.
- ollama serve: inicia o servidor Ollama em segundo plano, o que é necessário para que outras aplicações (como GUIs ou APIs) possam se conectar a ele.
CLI do Ollama é uma ferramenta robusta para quem busca controle e automação, permitindo a integração fácil em scripts e fluxos de trabalho.
Interface gráfica (GUI) e experiências mais amigáveis
Embora a CLI seja poderosa, nem todos os usuários se sentem confortáveis com ela. Felizmente, a comunidade Ollama e desenvolvedores independentes têm criado Interfaces Gráficas de Usuário (GUIs) que tornam a interação com os LLMs ainda mais amigável.
Essas GUIs geralmente oferecem:
- Chatbots intuitivos: semelhantes ao ChatGPT, com um campo de texto para digitar perguntas e uma área para as respostas do modelo;
- Gerenciamento de modelos: botões e menus para baixar, remover e selecionar modelos sem usar a linha de comando;
- Configurações avançadas: opções para ajustar parâmetros do modelo (como temperatura e comprimento da resposta) de forma visual;
- Integração com outras ferramentas: algumas GUIs podem oferecer recursos adicionais, como a capacidade de criar “personas” para os modelos ou integrar-se com serviços de terceiros.
Exemplos de GUIs populares incluem aplicativos desktop independentes que se conectam ao servidor Ollama em segundo plano. Eles são capazes de transformar a experiência, tornando o uso de LLMs locais acessível a um público muito mais amplo.
Para os desenvolvedores, a capacidade de integrar o Ollama com APIs significa que a lógica de negócio pode interagir diretamente com os modelos, abrindo um leque de possibilidades para criação de aplicativos inteligentes e personalizados.
Compatibilidade e requisitos técnicos
Para aproveitar ao máximo o Ollama, é importante entender os requisitos de hardware e software. Embora ele seja projetado para ser o mais acessível possível, alguns modelos podem exigir recursos mais parrudos.
Plataformas suportadas: Linux, macOS, Windows
O Ollama se destaca pela sua ampla compatibilidade, estando disponível para os principais sistemas operacionais do mercado:
- Linux: é uma plataforma nativa e onde o Ollama frequentemente tem o melhor desempenho, especialmente em servidores e máquinas com foco em desenvolvimento;
- macOS: totalmente suportado, com otimizações para os chips Apple Silicon (M1, M2, M3), que oferecem excelente desempenho para LLMs
- Windows: o Ollama também pode ser instalado no Windows, permitindo que usuários deste sistema operacional desfrutem dos benefícios de LLMs locais.
Essa versatilidade garante que a maioria dos usuários possa experimentar o Ollama, independentemente do sistema que utilizam em seus desktops ou notebooks.
Hardware recomendado: RAM, CPU e GPU
Os requisitos de hardware do Ollama dependem diretamente do tamanho do modelo que você pretende executar. Modelos de linguagem são intensivos em recursos, principalmente em memória RAM e, idealmente, em VRAM (memória da GPU).
- RAM (memória principal): é o requisito mais crítico. Modelos menores podem exigir a partir de 8GB de RAM, mas modelos mais complexos, como versões maiores do Llama 3, podem precisar de 16GB, 32GB ou até mais. Quanto mais RAM você tiver, maiores e mais complexos os modelos que poderá executar de forma eficiente;
- CPU (processador): um processador moderno com múltiplos núcleos é benéfico, mas a GPU (se disponível) geralmente fará o trabalho mais pesado;
- GPU (placa de vídeo): uma GPU dedicada com bastante VRAM é o que realmente acelera a execução de LLMs. Para uma experiência fluida, recomenda-se GPUs com pelo menos 8GB de VRAM, e o melhor é ter 12GB ou mais para modelos maiores. GPUs da NVIDIA com suporte a CUDA são as mais otimizadas, mas o Ollama também está expandindo o suporte para outras arquiteturas.
Para verificar os requisitos específicos de cada modelo, é sempre bom consultar a página do modelo no site oficial do Ollama ou na documentação da comunidade.
Suporte a GPUs dedicadas e interfaces como Vulkan ou CUDA
O Ollama é projetado para tirar o máximo proveito do hardware disponível, e o suporte a GPUs dedicadas é um diferencial.
- CUDA (NVIDIA): se você possui uma placa de vídeo NVIDIA, o Ollama se integra perfeitamente com a plataforma CUDA, que é o padrão da indústria para computação de alto desempenho em GPUs;
- Metal (Apple Silicon): para usuários de Macs com chips M1, M2 ou M3, o Ollama utiliza a API Metal da Apple, otimizando a execução dos modelos para o hardware integrado e oferecendo um desempenho surpreendente mesmo sem uma GPU dedicada tradicional;
- Vulkan: o suporte a Vulkan está em desenvolvimento e expandindo, o que permitirá ao Ollama aproveitar GPUs de outras fabricantes (como AMD e Intel) de forma mais eficiente no futuro.
A capacidade de alavancar o poder da GPU é o que diferencia uma experiência fluida de uma lenta ao lidar com LLMs. Para maior proveito, certifique-se de que seus drivers de vídeo estejam atualizados para garantir a melhor compatibilidade e desempenho com o Ollama.
Tem interesse em conhecer mais? Veja como instalar o Ollama a seguir:
Modelos e usos comuns com Ollama
O Ollama não é apenas uma plataforma para executar LLMs; é um portal para uma vasta biblioteca de modelos de linguagem que podem ser utilizados em diversas aplicações. A flexibilidade da ferramenta permite que usuários e desenvolvedores explorem o potencial da IA de maneiras inovadoras e personalizadas.
Modelos disponíveis
Uma das maiores forças do Ollama é o acesso facilitado a uma diversidade crescente de modelos de linguagem de ponta. A comunidade de IA de código aberto está em constante evolução, e o Ollama atua como um agregador, disponibilizando esses modelos para uso local. Alguns dos mais populares incluem:
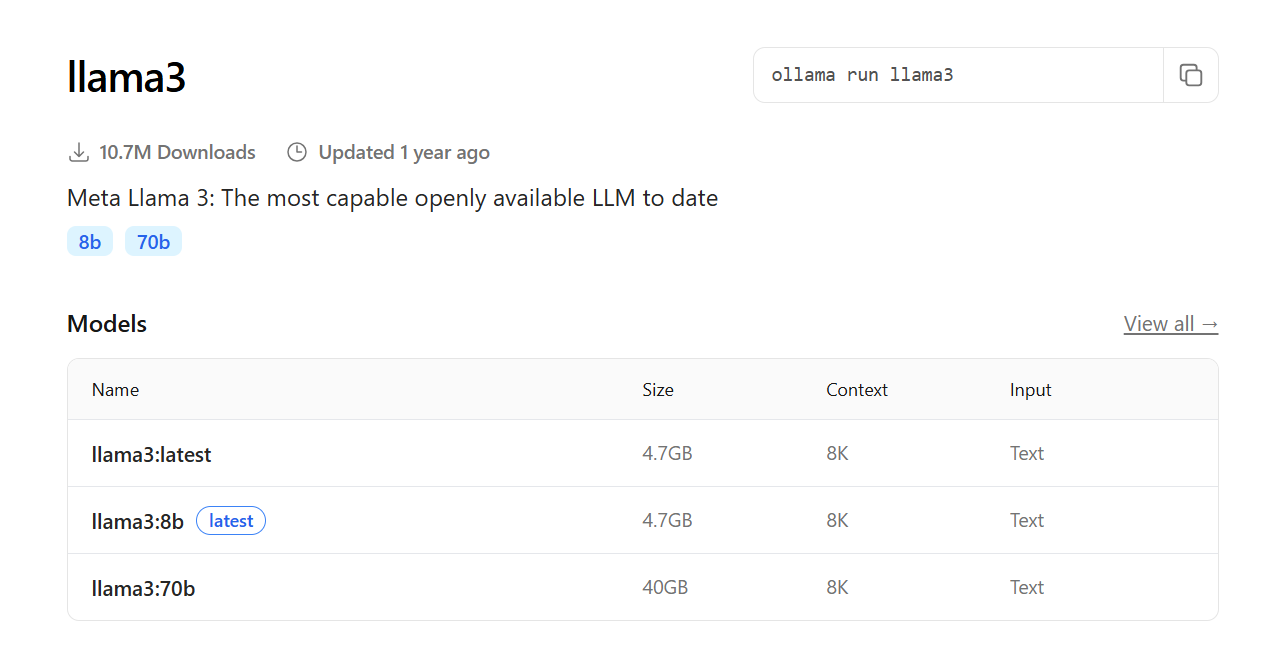
- Llama 3: desenvolvido pela Meta, o Llama 3 é um dos modelos mais avançados e versáteis disponíveis, com excelente desempenho em uma variedade de tarefas de linguagem. O Ollama oferece diferentes tamanhos do Llama 3, permitindo escolher o equilíbrio entre desempenho e requisitos de hardware;
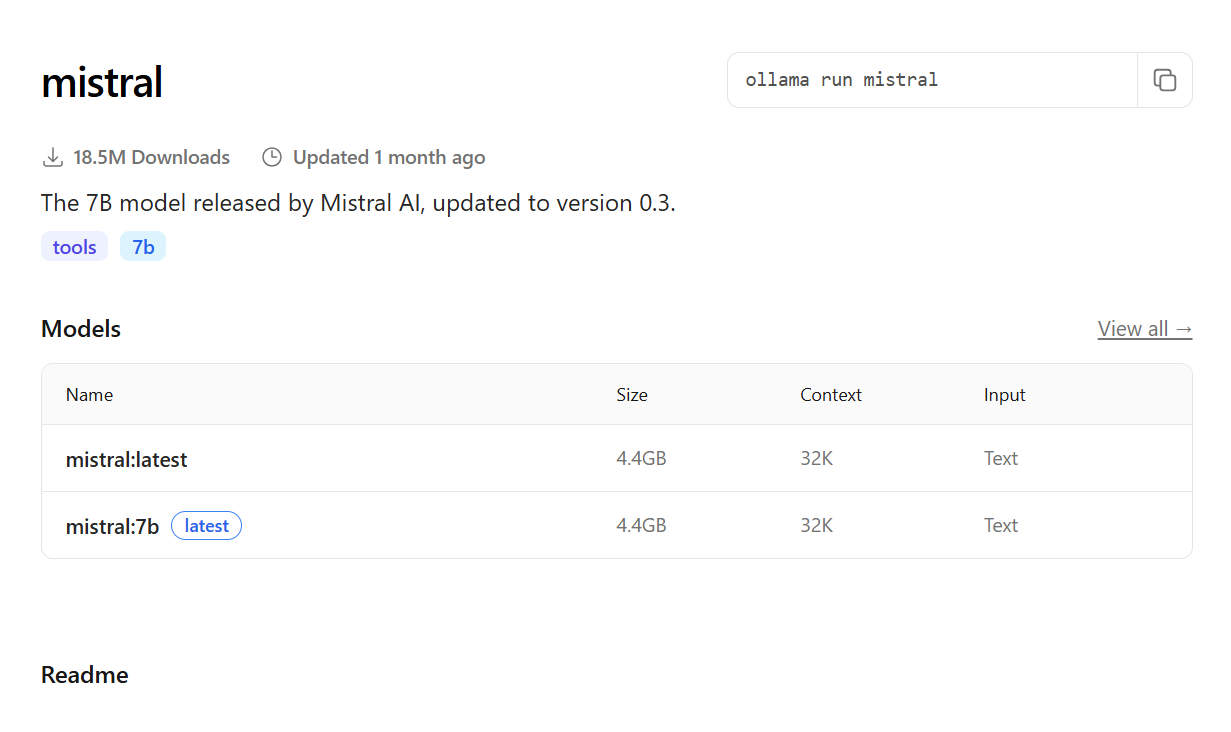
- Mistral: conhecido por sua eficiência e alta qualidade de resposta, mesmo em modelos menores, o Mistral tem se tornado uma escolha popular para muitas aplicações.
- Gemma: lançado pelo Google, o Gemma é uma família de modelos leves e de código aberto, projetados para serem eficientes e serem ideais para experimentação e uso local;
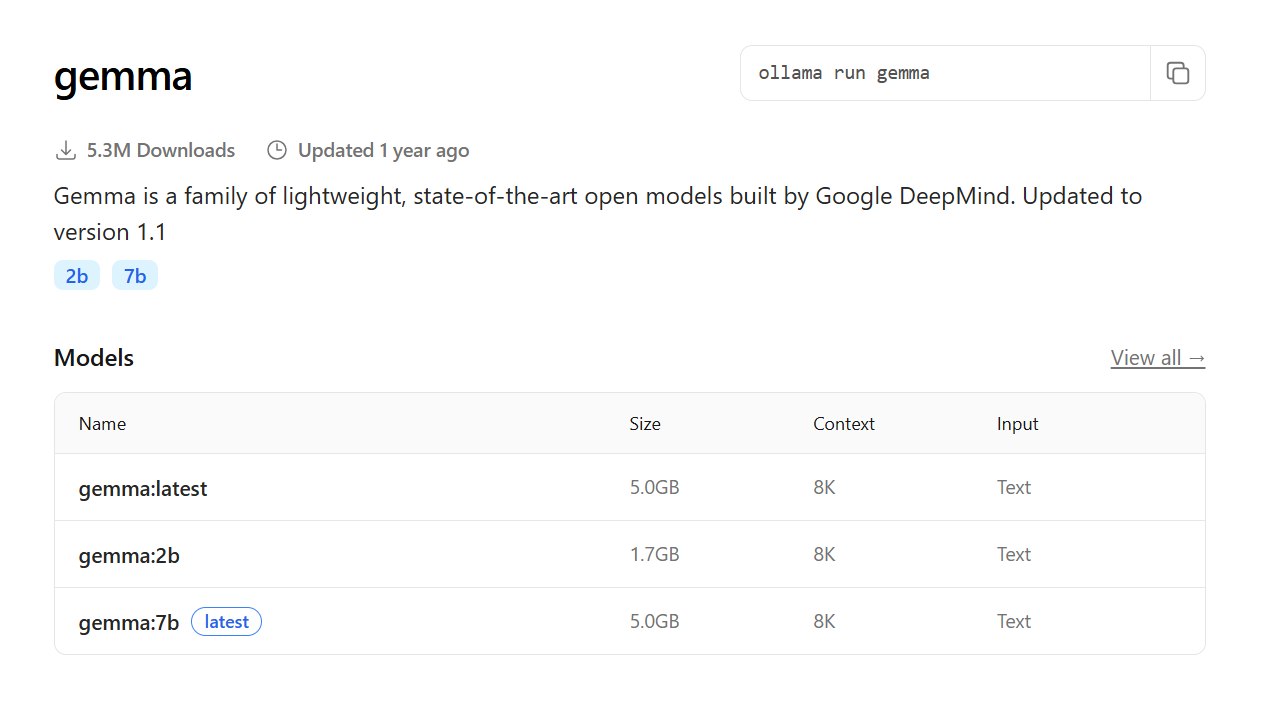
- Phi-3: outro modelo compacto, mas capaz, desenvolvido pela Microsoft, excelente para tarefas que exigem respostas rápidas com recursos limitados;
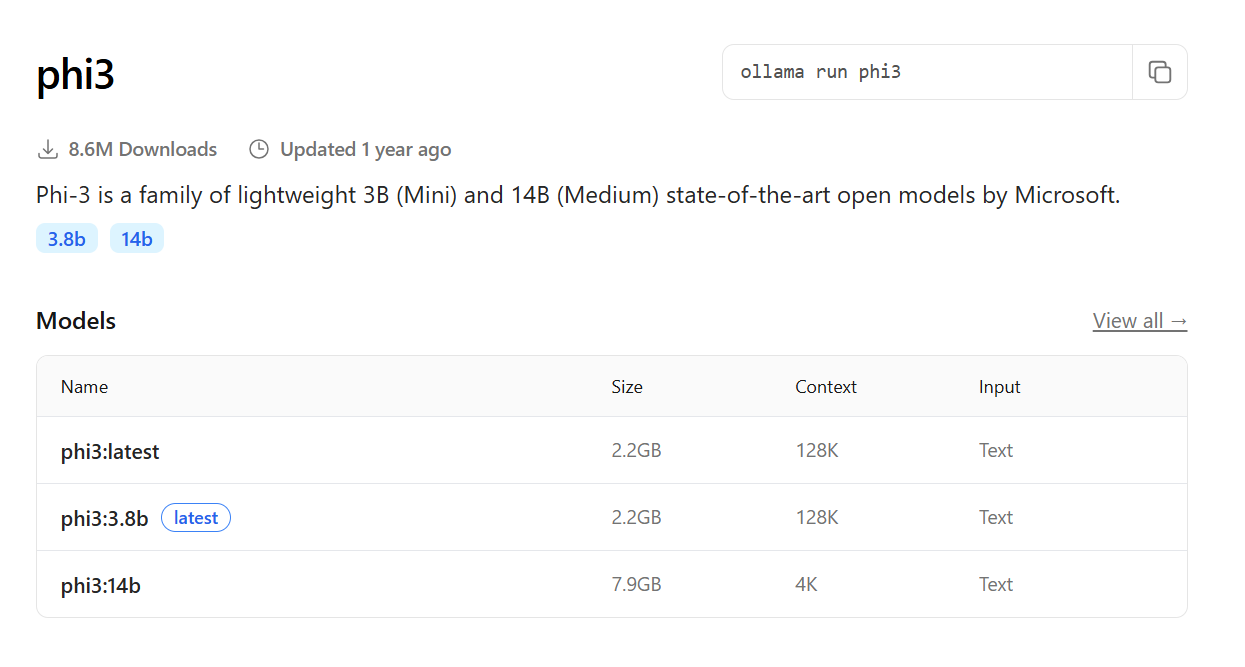
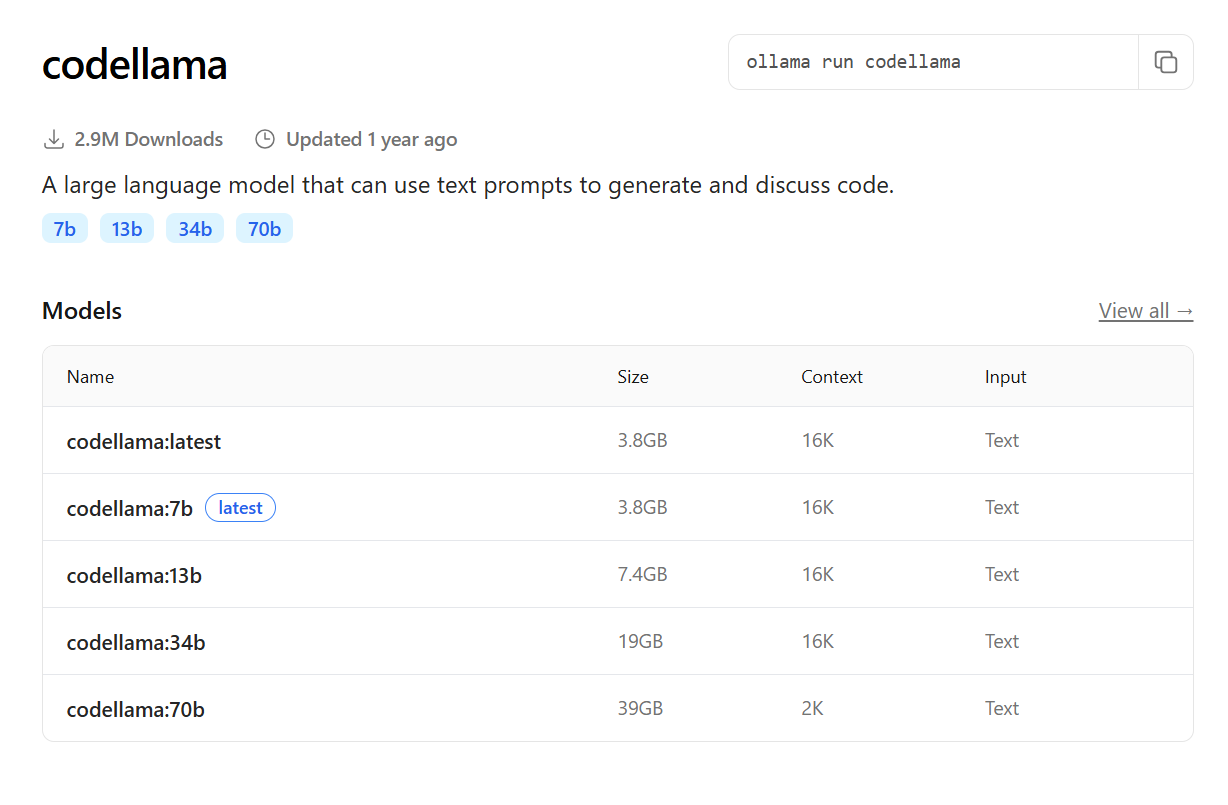
- Codellama: uma versão do Llama otimizada especificamente para geração e compreensão de código, útil para desenvolvedores.
Além desses, o repositório do Ollama está sempre sendo atualizado com novos modelos e versões otimizadas. Você pode explorar a lista completa de modelos disponíveis na página oficial do Ollama, onde cada modelo vem com uma breve descrição e seus requisitos.
Aplicações típicas
A capacidade de executar LLMs localmente abre um leque de possibilidades para diversas aplicações. Sendo assim, o Ollama se torna uma ferramenta fundamental para:
- Chatbots e assistentes pessoais: crie seu próprio chatbot com privacidade total, que pode responder a perguntas, gerar texto criativo, resumir documentos e até mesmo ajudar no brainstorming de ideias, tudo sem que seus dados saiam do seu computador;
- Desenvolvimento e prototipagem: desenvolvedores podem usar o Ollama para testar rapidamente novas ideias e funcionalidades baseadas em LLMs, sem depender de APIs externas ou incorrer em custos de nuvem. É ideal para prototipar aplicações de IA, integrar modelos em softwares existentes ou criar ferramentas personalizadas;
- Geração de conteúdo: use os modelos para auxiliar na escrita de artigos, e-mails, roteiros ou qualquer tipo de conteúdo textual, acelerando o processo criativo e garantindo a originalidade do material;
- Resumo e análise de documentos: processar documentos locais para extrair informações importantes, resumir textos longos ou identificar padrões, tudo com a garantia de que seus documentos permanecem confidenciais;
- Programação e automação: com modelos como o CodeLlama, desenvolvedores podem gerar código, refatorar trechos, depurar problemas e até mesmo aprender novas linguagens, tudo assistido por um LLM local;
- Aprendizado e experimentação: para estudantes e entusiastas de IA, o Ollama é uma plataforma excelente para entender como os LLMs funcionam na prática, experimentar diferentes modelos e explorar suas capacidades sem a complexidade de configurações avançadas;
- Pesquisa e análise de dados: em ambientes onde a confidencialidade dos dados é primordial, o Ollama permite a análise de grandes volumes de texto, identificação de tendências e suporte à tomada de decisões, mantendo tudo dentro dos limites seguros da sua infraestrutura.
A versatilidade do Ollama o torna uma ferramenta valiosa para qualquer pessoa interessada em aproveitar o poder da inteligência artificial de forma controlada e eficiente.
Do Ollama aos Agentes de IA: acessibilidade e resultados reais
Assim como o Ollama coloca o poder dos Modelos de Linguagem diretamente em suas mãos, a HostGator também aposta em soluções que tornam a inteligência artificial mais acessível para qualquer empreendedor. Um exemplo são os Agentes de IA da HostGator, que automatizam processos como configurar domínios, ajustar e-mails, criar conteúdos e gerenciar tarefas do dia a dia digital.
Enquanto o Ollama abre portas para quem deseja explorar o universo dos LLMs de forma local e segura, os agentes da HostGator transformam essa tecnologia em resultados práticos para o crescimento de negócios online.

Conclusão
O Ollama representa um marco importante na democratização do acesso aos Modelos de Linguagem Grandes, levando o poder da inteligência artificial diretamente para o seu computador.
Ao permitir a execução local de LLMs, ele garante privacidade, controle e desempenho superiores, oferecendo uma alternativa que muitas vezes supera as soluções em nuvem, além de entregar um bom custo-benefício.
Com uma instalação simplificada e uma comunidade em constante expansão, o Ollama torna mais fácil e seguro explorar todo o potencial da inteligência artificial na prática.
Conferir também: